5 Methods To Find All URLs from A Domain

Discover 5 effective methods to extract all URLs from any website domain, including sitemaps, crawling tools, custom scripts, and automated APIs for SEO analysis and competitor research.
Finding all URLs on a domain can be difficult, but with the right approach and tools, you can easily extract pages from a website.
In this article, I'll walk you through a few easy ways to extract URLs from any site.
And if you're looking to automate or scale things up, stick around till the end, I'll share a method (plus a free tool that I created) that does so.
5 Best Ways To Find All URLs from A Website
Each method used here can be used for free!
Let's start off with the first method!
Using Sitemap of Domain
Sitemap is a collection of all the URLs a domain has. So if you can access the sitemap, you usually have the list of all URLs. (Other than the no-indexed ones)
Where you can find sitemap?
Usually the sitemap would be found in the robots.txt file of a domain.
The robots.txt file can be found on mywebsite.com/robots.txt & the sitemap/s would be listed here.
This file is where we define rules for bots and give them the URLs of sitemap for them to access it.
For example, the robots.txt file for my website can be found in https://www.capturekit.dev/robots.txt
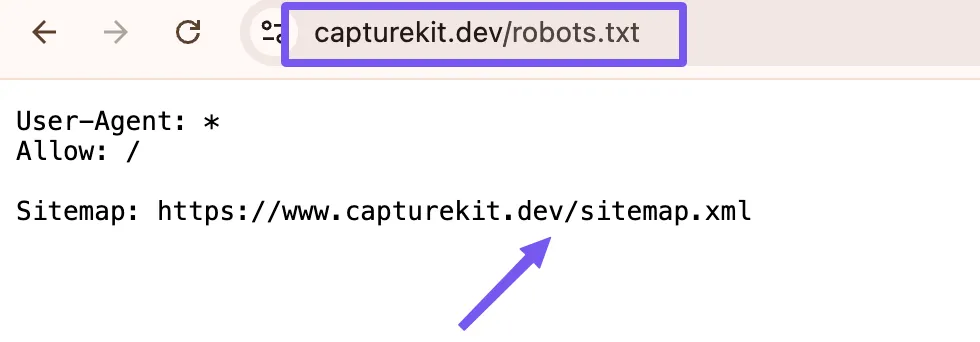
Now when you get into this URL, all indexed URLs of the website will be found.
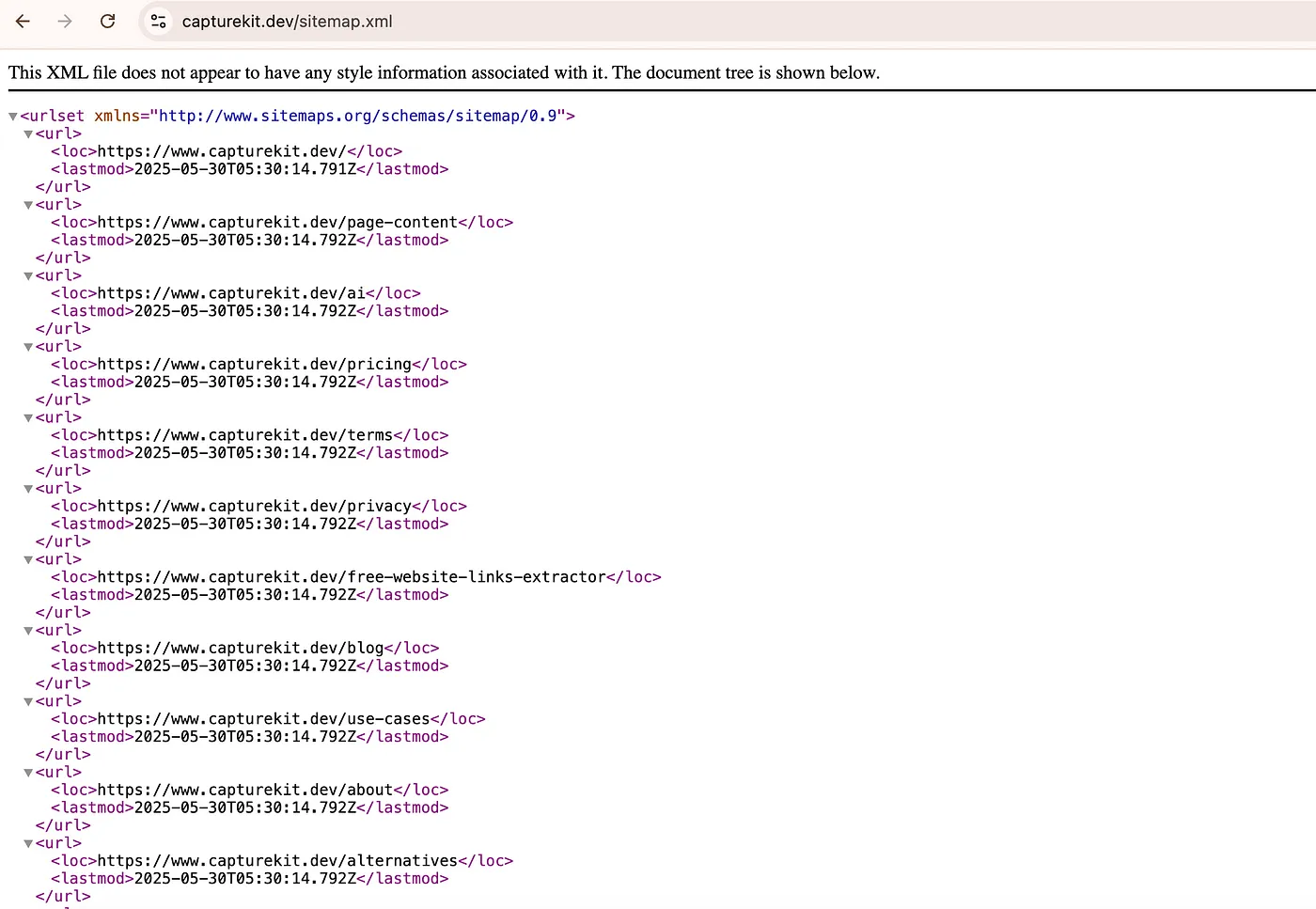
There can be multiple sitemaps for a website, usually website with multiple category or pages.
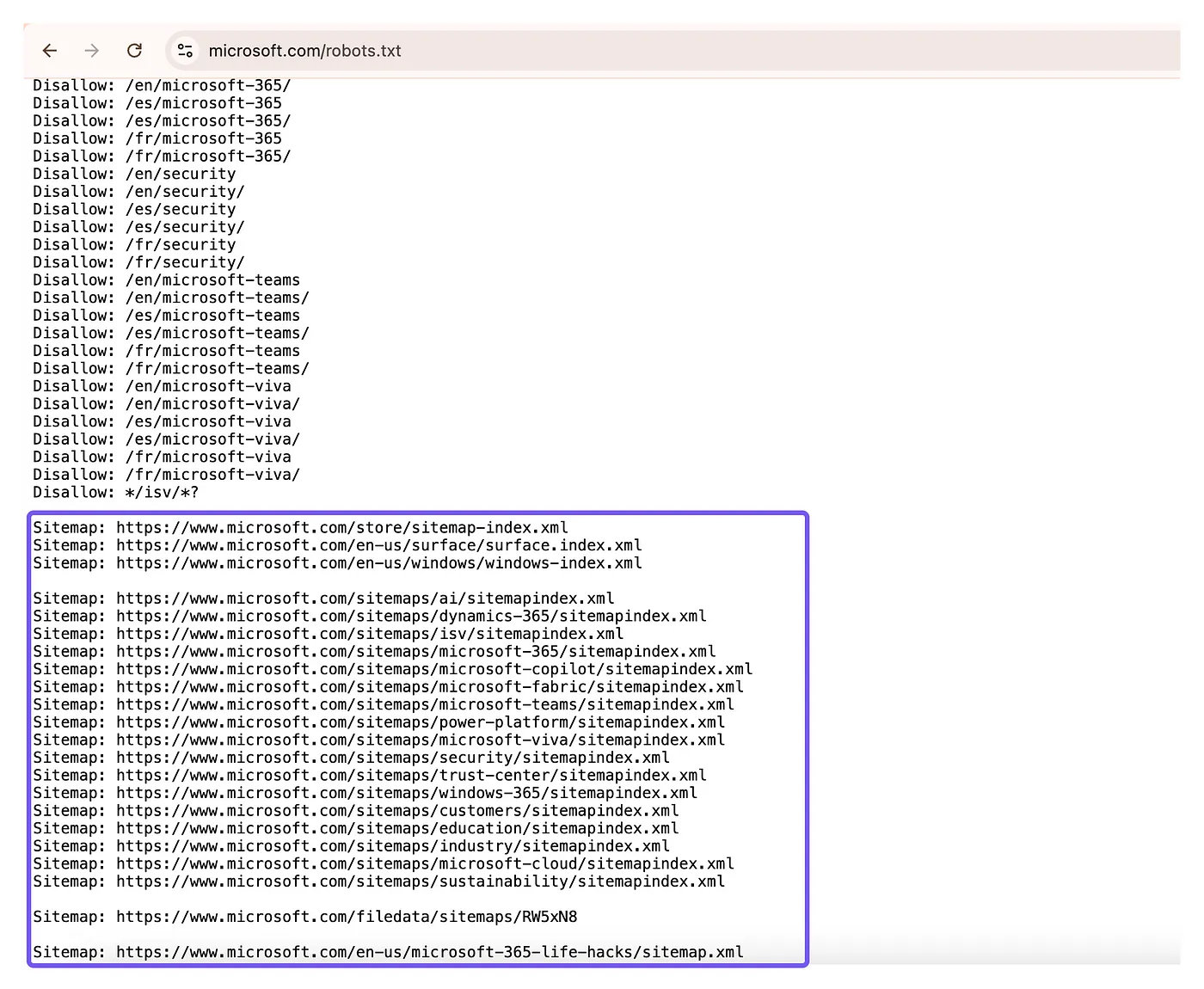
For example, Microsoft has many sitemaps, and all on their robots.txt
Pros of using Sitemap
- Quick access to most URLs: Sitemaps usually contain a comprehensive list of a website's pages - no need to crawl the whole site.
- Often includes useful metadata: You get info like last modified date, which can be handy for further analysis.
Cons of Using Sitemap
- Not always available: Not every website lists its sitemap in
robots.txt-some don't have a sitemap at all. - Scalability is limited: For bulk operations across many domains, manually finding and downloading sitemaps becomes a hassle.
Here's a tip - If you don't find sitemap in robots.txt, you can do the other way around i.e. create a sitemap using free sitemap generators & download them in CSV.
Screamingfrog
Screamingfrog is a crawling tool that helps you to do domain analysis.
One of the analysis it gives is URLs on a domain.
If your soul purpose or you haven't used this tool before, this can be a little tricky.
Also, you need to download the software to your machine, it isn't a SaaS product, there is app for Windows & Mac.
The free version, offers 500 URLs to see and extract in a CSV file.
Pros of using Screamingfrog
- Free Version - Can offer 500 URLs
- Finds URLs beyond Google's index: Screaming Frog crawls every link it can find on your site, even those not indexed by Google.
Cons of using Screamingfrog
- Not made for bulk domains: It's really built for one site at a time. If you want URLs from lots of domains, it gets tedious. Yes, the API is available, but if your sole purpose is to extract URLs the cost with this API is not worth it.
- Learning curve: The interface has a lot of options, which can be overwhelming for first-timers.
Using Custom Script with NodeJs
The first method we will use is to extract sitemap links. Here are the steps involved:
- Find the sitemap URL (usually at
/sitemap.xml) - Fetch and parse the XML content
- Extract the links from the parsed XML
We will be using axios and xml2js libraries:
import axios from 'axios';
import { parseStringPromise } from 'xml2js';
// Maximum number of links to fetch
const MAX_LINKS = 100;
// Main function to find and extract sitemap links
async function extractSitemapLinks(url) {
try {
// Step 1: Find the sitemap URL
const sitemapUrl = await getSitemapUrl(url);
if (!sitemapUrl) {
console.log('No sitemap found for this website');
return [];
}
// Step 2: Fetch links from the sitemap
const links = await fetchSitemapLinks(sitemapUrl);
return links;
} catch (error) {
console.error('Error extracting sitemap links:', error);
return [];
}
}
// Function to determine the sitemap URL
export async function getSitemapUrl(url) {
try {
const { origin, fullPath } = formatUrl(url);
// If the URL already points to an XML file, verify if it's a valid sitemap
if (fullPath.endsWith('.xml')) {
const isValidSitemap = await verifySitemap(fullPath);
return isValidSitemap ? fullPath : null;
}
// Common sitemap paths to check in order of popularity
const commonSitemapPaths = [
'/sitemap.xml',
'/sitemap_index.xml',
'/sitemap-index.xml',
'/sitemaps.xml',
'/sitemap/sitemap.xml',
'/sitemaps/sitemap.xml',
'/sitemap/index.xml',
'/wp-sitemap.xml', // WordPress
'/sitemap_news.xml', // News specific
'/sitemap_products.xml', // E-commerce
'/post-sitemap.xml', // Blog specific
'/page-sitemap.xml', // Page specific
'/robots.txt', // Sometimes sitemap URL is in robots.txt
];
// Try each path in order
for (const path of commonSitemapPaths) {
// If we're checking robots.txt, we need to extract the sitemap URL from it
if (path === '/robots.txt') {
try {
const robotsUrl = `${origin}${path}`;
const robotsResponse = await axios.get(robotsUrl);
const robotsContent = robotsResponse.data;
// Extract sitemap URL from robots.txt
const sitemapMatch = robotsContent.match(/Sitemap:\s*(.+)/i);
if (sitemapMatch && sitemapMatch[1]) {
const robotsSitemapUrl = sitemapMatch[1].trim();
const isValid = await verifySitemap(robotsSitemapUrl);
if (isValid) return robotsSitemapUrl;
}
} catch (e) {
// If robots.txt check fails, continue to the next option
continue;
}
} else {
const sitemapUrl = `${origin}${path}`;
const isValidSitemap = await verifySitemap(sitemapUrl);
if (isValidSitemap) return sitemapUrl;
}
}
return null;
} catch (error) {
console.error('Error determining sitemap URL:', error);
return null;
}
}
// Verify if a URL is a valid sitemap
export async function verifySitemap(sitemapUrl) {
try {
const response = await axios.get(sitemapUrl);
const parsedSitemap = await parseStringPromise(response.data);
// Check for <urlset> or <sitemapindex> tags
return Boolean(parsedSitemap.urlset || parsedSitemap.sitemapindex);
} catch (e) {
console.error(`Invalid sitemap at ${sitemapUrl}`);
return false;
}
}
// Format URL to ensure it has proper scheme and structure
export function formatUrl(url) {
if (!url.startsWith('http')) {
url = `https://${url}`;
}
const { origin, pathname } = new URL(url.replace('http:', 'https:'));
return {
origin,
fullPath: `${origin}${pathname}`.replace(/\/$/, ''),
};
}
// Fetch and process links from the sitemap
export async function fetchSitemapLinks(sitemapUrl, maxLinks = MAX_LINKS) {
const links = [];
try {
const response = await axios.get(sitemapUrl);
const sitemapContent = response.data;
const parsedSitemap = await parseStringPromise(sitemapContent);
// Handle sitemaps with <urlset>
if (parsedSitemap.urlset?.url) {
for (const urlObj of parsedSitemap.urlset.url) {
try {
if (links.length >= maxLinks) break;
links.push(urlObj.loc[0]);
} catch (e) {
console.error('Error parsing sitemap:', e);
}
}
}
// Handle nested sitemaps with <sitemapindex>
if (parsedSitemap.sitemapindex?.sitemap) {
for (const sitemapObj of parsedSitemap.sitemapindex.sitemap) {
try {
if (links.length >= maxLinks) break; // Stop processing further sitemaps
const nestedSitemapUrl = sitemapObj.loc[0];
const nestedLinks = await fetchSitemapLinks(
nestedSitemapUrl,
maxLinks - links.length
);
links.push(...nestedLinks.slice(0, maxLinks - links.length));
} catch (e) {
console.error('Error parsing sitemap:', e);
}
}
}
return links.slice(0, maxLinks);
} catch (error) {
console.error(`Error fetching sitemap from ${sitemapUrl}:`, error);
return links || [];
}
}
// Usage example
async function main() {
const url = 'https://example.com';
const links = await extractSitemapLinks(url);
console.log('Found links:', links);
}
main();
It simply, discovers the sitemap, validates it by checking the file, identify nested sitemap and finally extract the <loc> elements from both regular sitemaps and sitemap indexes.
I have written a dedicated tutorial on extracting links from sitemap using NodeJs.
The other method that you can use is by using a spider crawling technique.
Pros of using custom script
- Full control: You get to customise everything like fetching, parsing, error handling & tailored to your exact needs.
- Scalable: You can automate this for as many domains as you want - great for bulk jobs or agency work.
Cons of using custom script
- Requires coding: Not for non-technical users. You need at least basic Node.js and JavaScript skills.
- Initial setup time: Takes time to write, debug, and maintain your script (compared to using a ready-made tool).
Using Free Sitemap URL Extraction Tools
There are many free tools available, one which I made too. You can Export all the URLs in the tool itself in CSV file.
Here's the tool link, do test it out!
And yes there are more tools that you can test out, I tested them and here are some of them that I liked.
- https://seotesting.com/sitemap-url-extractor/
- https://growthackdigital.com/tools/extract-urls-from-sitemap-file/
Pros of using Free Tools
- Free to use: No cost or sign-up barriers - anyone can try it out instantly.
- Easy for everyone: No coding or software install needed, just use the online tool.
- Flexible: Lets you extract links from a sitemap or by crawling a page, so you have options.
Cons of using Free Tools
- Single domain at a time: Designed for extracting links from one website at a time, not bulk domains.
- Not scalable for big operations: If you need to process hundreds of domains or automate workflows, this manual tool isn't ideal.
Using CaptureKit API
Now all of the above methods told are just fantastic ways to extract links from a domain. However, I am assuming that this won't be a single time process.
And therefore a better way is to automate this process using CaptureKit Page Content API.
This API allows you to take structured data from webpages, you can read the documentation here to understand better how this API works and its parameters.
The **include_sitemap** **parameter allows you to extract the sitemap and all the URLs in it. All sitemaps are extracted with links they have.
You get 100 free credits when you first sign up to test the API.
You can quickly check the API in our Request builder, below is a small GIF that shows it ⬇️
Conclusion
Extracting URLs from a domain can be real handy for many use cases. Be it done for SEO audits, competitor research, checking what topics the competitor have covered the most or for security check.
Knowing which method would work best for you ultimately depends on your use case.
Again, if you want to do it for hundreds of domain, you can scale up this process using CaptureKit Page Content API.
If you need any help in setting this up, you can reach out to me on website's chat & I would be happy to help!!
Ready to get started with CaptureKit?
Start capturing screenshots and extracting content today. Get started for free.
Get StartedYou Might Also Like
How to Extract All Links from a Website Using Puppeteer
Learn how to extract all links from a website using Puppeteer, and discover an easier alternative using CaptureKit API
CaptureKit is becoming part of WebAPI Group
We're thrilled to announce that CaptureKit is becoming part of WebAPI Group, bringing our screenshot API technology to their comprehensive API ecosystem.
How To Capture & Convert a Screenshot into PDF
Learn how to capture and convert screenshots into PDFs easily using tools, APIs, and automation workflows. Perfect for reports, documentation, and sharing visuals.